Customizing task resources¶
One of the reasons to use a hosted Flyte environment is the potential of leveraging CPU, memory and storage resources, far greater than what’s available locally. Flytekit makes it possible to specify these requirements declaratively and close to where the task itself is declared.
In this example, the memory required by the function increases as the dataset size increases. Large datasets may not be able to run locally, so we would want to provide hints to the Flyte backend to request for more memory. This is done by decorating the task with the hints as shown in the following code sample.
Tasks can have requests and limits which mirror the native equivalents in Kubernetes.
A task can possibly be allocated more resources than it requests, but never more than its limit.
Requests are treated as hints to schedule tasks on nodes with available resources, whereas limits
are hard constraints.
For either a request or limit, refer to the flytekit.Resources documentation.
The following attributes can be specified for a Resource.
cpumemgpu
To ensure that regular tasks that don’t require GPUs are not scheduled on GPU nodes, a separate node group for GPU nodes can be configured with taints.
To ensure that tasks that require GPUs get the needed tolerations on their pods, set up FlytePropeller using the following configuration. Ensure that this toleration config matches the taint config you have configured to protect your GPU providing nodes from dealing with regular non-GPU workloads (pods).
The actual values follow the Kubernetes convention. Let’s look at an example to understand how to customize resources.
Note
To clone and run the example code on this page, see the Flytesnacks repo.
Import the dependencies:
import typing
from flytekit import Resources, task, workflow
Define a task and configure the resources to be allocated to it:
@task(
requests=Resources(cpu="1", mem="100Mi", ephemeral_storage="200Mi"),
limits=Resources(cpu="2", mem="150Mi", ephemeral_storage="500Mi"),
)
def count_unique_numbers(x: typing.List[int]) -> int:
s = set()
for i in x:
s.add(i)
return len(s)
Define a task that computes the square of a number:
@task
def square(x: int) -> int:
return x * x
You can use the tasks decorated with memory and storage hints like regular tasks in a workflow.
@workflow
def my_workflow(x: typing.List[int]) -> int:
return square(x=count_unique_numbers(x=x))
You can execute the workflow locally.
if __name__ == "__main__":
print(count_unique_numbers(x=[1, 1, 2]))
print(my_workflow(x=[1, 1, 2]))
Note
To alter the limits of the default platform configuration, change the admin config and namespace level quota on the cluster.
Using with_overrides¶
You can use the with_overrides method to override the resources allocated to the tasks dynamically.
Let’s understand how the resources can be initialized with an example.
Import the dependencies.
import typing # noqa: E402
from flytekit import Resources, task, workflow # noqa: E402
Define a task and configure the resources to be allocated to it. You can use tasks decorated with memory and storage hints like regular tasks in a workflow.
@task(
requests=Resources(cpu="1", mem="100Mi", ephemeral_storage="200Mi"),
limits=Resources(cpu="2", mem="150Mi", ephemeral_storage="500Mi"),
)
def count_unique_numbers(x: typing.List[int]) -> int:
s = set()
for i in x:
s.add(i)
return len(s)
Define a task that computes the square of a number:
@task
def square_1(x: int) -> int:
return x * x
The with_overrides method overrides the old resource allocations:
@workflow
def my_pipeline(x: typing.List[int]) -> int:
return square_1(x=count_unique_numbers_1(x=x)).with_overrides(limits=Resources(cpu="6", mem="500Mi"))
You can execute the workflow locally:
if __name__ == "__main__":
print(count_unique_numbers_1(x=[1, 1, 2]))
print(my_pipeline(x=[1, 1, 2]))
You can see the memory allocation below. The memory limit is 500Mi rather than 350Mi, and the
CPU limit is 4, whereas it should have been 6 as specified using with_overrides.
This is because the default platform CPU quota for every pod is 4.
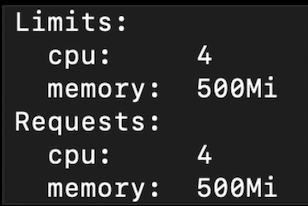
Resource allocated using “with_overrides” method¶