Forecasting Rossman Store Sales with Horovod and Spark¶
The problem statement we will be looking at is forecasting sales using rossmann store sales data. Our example is an adaptation of the Horovod-Spark example. Here’s how the code is streamlined:
Fetch the rossmann sales data
Perform complicated data pre-processing using Flyte-Spark plugin
Define a Keras model and perform distributed training using Horovod on Spark
Generate predictions and store them in a submission file
About Horovod¶
Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. It uses the all-reduce algorithm for fast distributed training instead of a parameter server approach. It builds on top of low-level frameworks like MPI and NCCL and provides optimized algorithms for sharing data between parallel training processes.
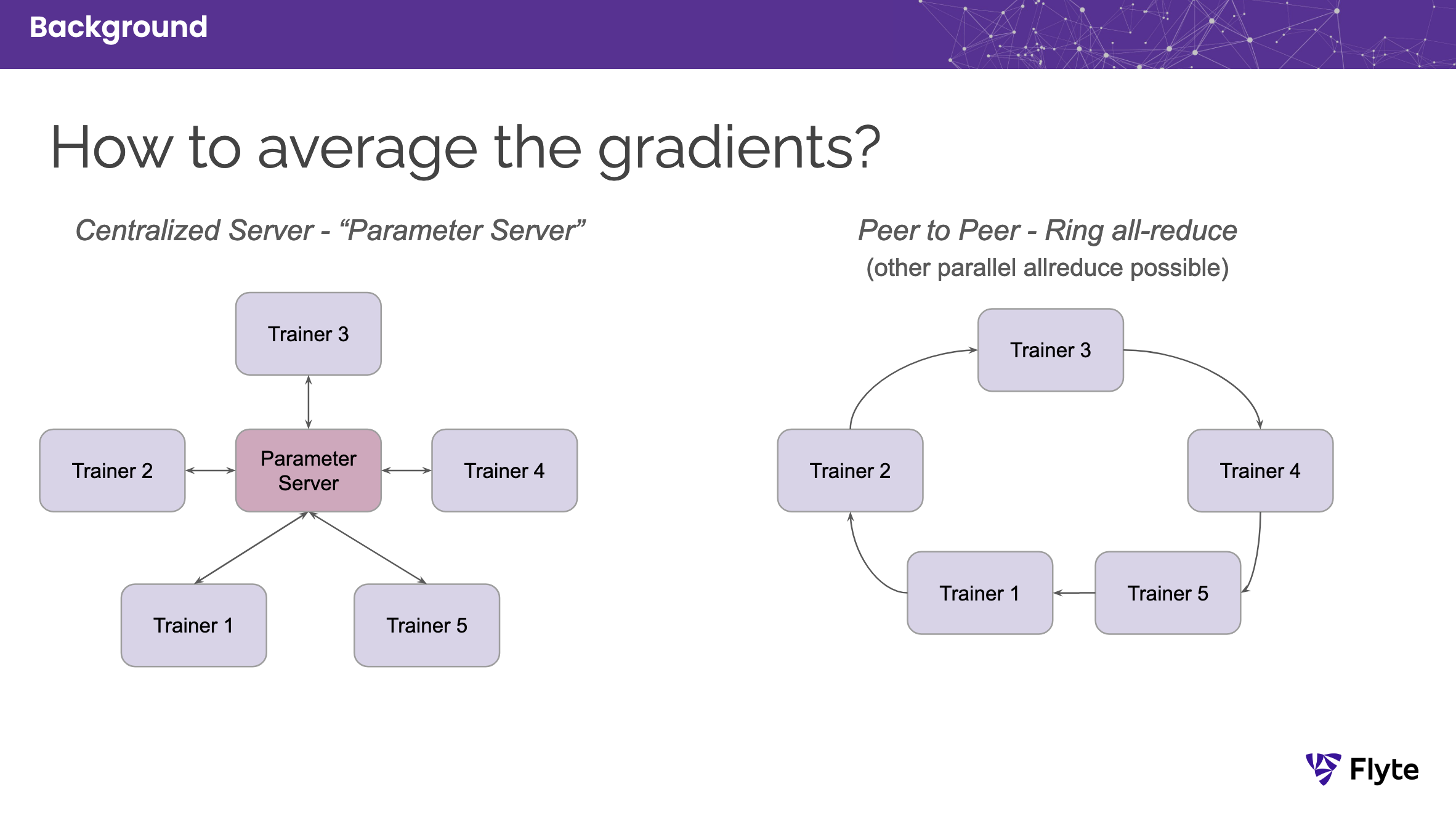
Parameter server vs. all-reduce¶
About Spark¶
Spark is a data processing and analytics engine to deal with large-scale data.
Here’s an interesting fact about Spark integration:
Spark integrates with both Horovod and Flyte
Horovod and Spark¶
Horovod implicitly supports Spark—it provides the horovod.spark package.
It facilitates running distributed jobs on the Spark cluster.
In our example, we use an Estimator API.
An estimator API abstracts the data processing, model training and checkpointing, and distributed training, which makes it easy to integrate and run our example code.
Since we use the Keras deep learning library, here’s how we install the relevant Horovod packages:
HOROVOD_WITH_MPI=1 HOROVOD_WITH_TENSORFLOW=1 pip install --no-cache-dir horovod[spark,tensorflow]==0.22.1
The installation includes enabling MPI and TensorFlow environments.
Flyte and Spark¶
Flyte can execute Spark jobs natively on a Kubernetes Cluster, which manages a virtual cluster’s lifecycle, spin-up, and tear down. It leverages the open-sourced Spark On K8s Operator and can be enabled without signing up for any service. This is like running a transient spark cluster—a type of cluster spun up for a specific Spark job and torn down after completion.
To install the Spark plugin on Flyte, we use the following command:
pip install flytekitplugins-spark
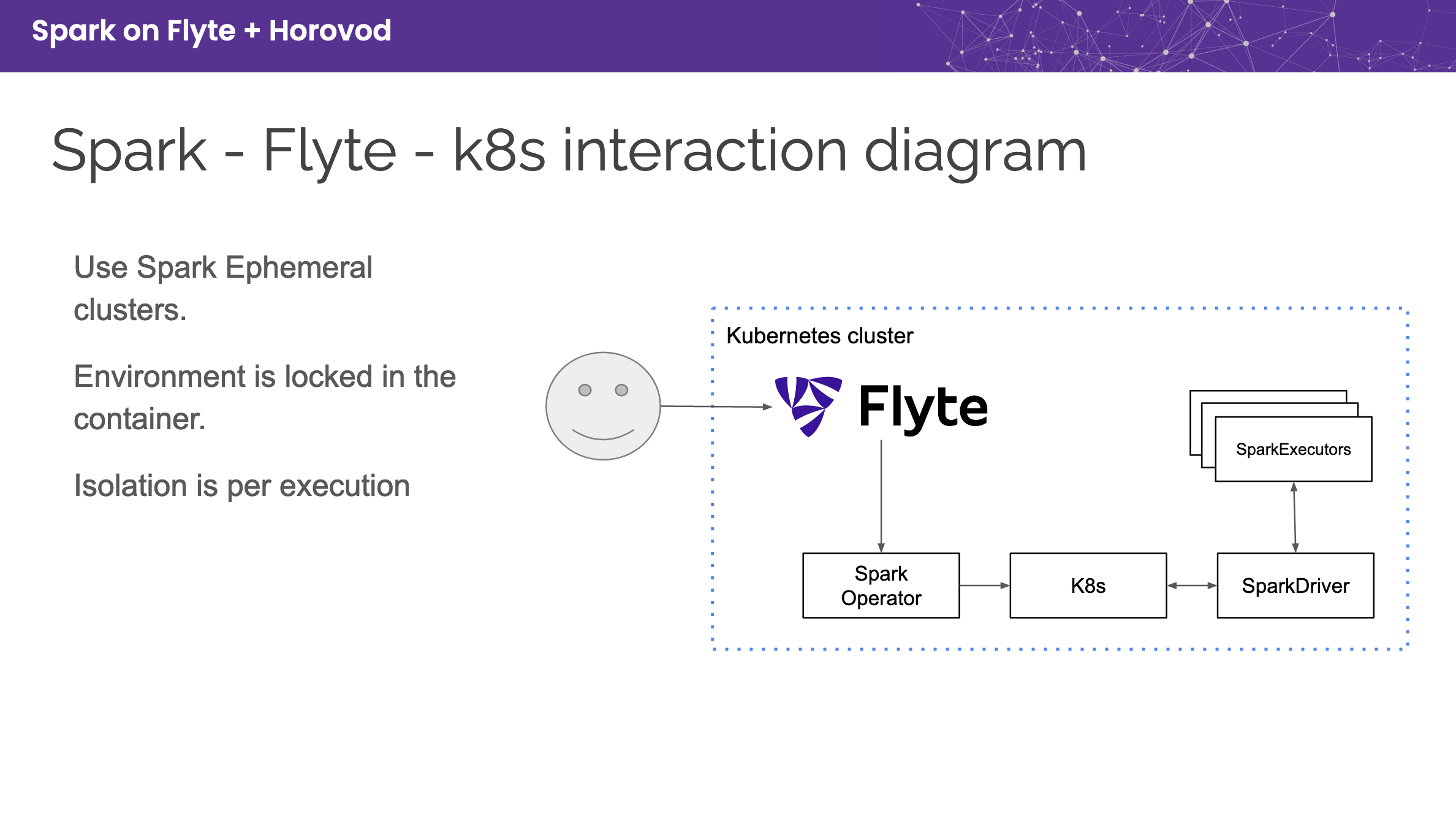
Flyte-Spark plugin¶
The plugin requires configuring the Flyte backend as well. Refer to Kubernetes Spark Jobs for setup instructions.
In a nutshell, here’s how Horovod-Spark-Flyte can be beneficial:
Horovod provides the distributed framework, Spark enables extracting, preprocessing, and partitioning data, Flyte can stitch the former two pieces together, e.g., by connecting the data output of a Spark transform to a training system using Horovod while ensuring high utilization of GPUs!
Run workflows in this directory with the custom-built base image like so:
pyflyte run --remote forecasting_sales/keras_spark_rossmann_estimator.py horovod_spark_wf --image ghcr.io/flyteorg/flytecookbook:spark_horovod-latest