Authoring Structure¶
Flytekit’s main focus is to provide users with the ability to create their own tasks and workflows. In this section, we’ll take a closer look at how it works under the hood.
Types and Type Engine¶
Flyte uses its own type system, which is defined in the IDL.
Despite being a dynamic language, Python also has its own type system which is primarily explained in PEP 484.
Therefore, Flytekit needs to establish a means of bridging the gap between these two type systems.
This is primariliy accomplished through the use of flytekit.extend.TypeEngine.
The TypeEngine works by invoking a series of TypeTransformers.
Each transformer is responsible for providing the functionality that the engine requires for a given native Python type.
Callable Entities¶
The Flyte user experience is built around three main concepts: Tasks, workflows, and launch plans. Each of these concepts is supported by one or more Python classes, which are instantiated by decorators (in the case of tasks and workflows) or a regular Python call (in the case of launch plans).
Tasks¶
Here is the existing hierarchy of task classes:
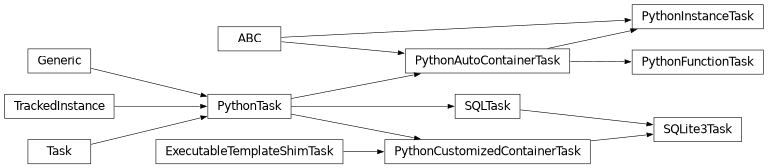
For more information on each of the classes, please refer to the corresponding documentation.
- class flytekit.core.base_task.Task(task_type, name, interface, metadata=None, task_type_version=0, security_ctx=None, docs=None, **kwargs)[source]
The base of all Tasks in flytekit. This task is closest to the FlyteIDL TaskTemplate and captures information in FlyteIDL specification and does not have python native interfaces associated. Refer to the derived classes for examples of how to extend this class.
- Parameters:
task_type (str)
name (str)
interface (TypedInterface)
metadata (TaskMetadata | None)
security_ctx (SecurityContext | None)
docs (Documentation | None)
- class flytekit.core.base_task.PythonTask(*args, **kwargs)[source]
Base Class for all Tasks with a Python native
Interface. This should be directly used for task types, that do not have a python function to be executed. Otherwise refer toflytekit.PythonFunctionTask.
- class flytekit.core.python_auto_container.PythonAutoContainerTask(*args, **kwargs)[source]
A Python AutoContainer task should be used as the base for all extensions that want the user’s code to be in the container and the container information to be automatically captured. This base will auto configure the image and image version to be used for all its derivatives.
If you are looking to extend, you might prefer to use
PythonFunctionTaskorPythonInstanceTask
- class flytekit.core.python_function_task.PythonFunctionTask(*args, **kwargs)[source]
A Python Function task should be used as the base for all extensions that have a python function. It will automatically detect interface of the python function and when serialized on the hosted Flyte platform handles the writing execution command to execute the function
It is advised this task is used using the @task decorator as follows
In the above code, the name of the function, the module, and the interface (inputs = int and outputs = str) will be auto detected.
Workflows¶
There exist two workflow classes, both of which derive from the WorkflowBase class.
- class flytekit.core.workflow.PythonFunctionWorkflow(*args, **kwargs)[source]
Please read Workflows first for a high-level understanding of what workflows are in Flyte. This Python object represents a workflow defined by a function and decorated with the
@workflowdecorator. Please see notes on that object for additional information.
- class flytekit.core.workflow.ImperativeWorkflow(name, failure_policy=None, interruptible=False)[source]
An imperative workflow is a programmatic analogue to the typical
@workflowfunction-based workflow and is better suited to programmatic applications.Assuming you have some tasks like so
@task def t1(a: str) -> str: return a + " world" @task def t2(): print("side effect")
You could create a workflow imperatively like so
# Create the workflow with a name. This needs to be unique within the project and takes the place of the function # name that's used for regular decorated function-based workflows. wb = Workflow(name="my_workflow") # Adds a top level input to the workflow. This is like an input to a workflow function. wb.add_workflow_input("in1", str) # Call your tasks. node = wb.add_entity(t1, a=wb.inputs["in1"]) wb.add_entity(t2) # This is analogous to a return statement wb.add_workflow_output("from_n0t1", node.outputs["o0"])
This workflow would be identical on the back-end to
nt = typing.NamedTuple("wf_output", [("from_n0t1", str)]) @workflow def my_workflow(in1: str) -> nt: x = t1(a=in1) t2() return nt(x)
Note that the only reason we need the
NamedTupleis so we can name the output the same thing as in the imperative example. The imperative paradigm makes the naming of workflow outputs easier, but this isn’t a big deal in function-workflows because names tend to not be necessary.- Parameters:
name (str)
failure_policy (Optional[WorkflowFailurePolicy])
interruptible (bool)
Launch Plans¶
There exists one LaunchPlan class.
- class flytekit.core.launch_plan.LaunchPlan(name, workflow, parameters, fixed_inputs, schedule=None, notifications=None, labels=None, annotations=None, raw_output_data_config=None, max_parallelism=None, security_context=None, trigger=None, overwrite_cache=None)[source]
Launch Plans are one of the core constructs of Flyte. Please take a look at the discussion in the core concepts if you are unfamiliar with them.
Every workflow is registered with a default launch plan, which is just a launch plan with none of the additional attributes set - no default values, fixed values, schedules, etc. Assuming you have the following workflow
@workflow def wf(a: int, c: str) -> str: ...
Create the default launch plan with
LaunchPlan.get_or_create(workflow=my_wf)
If you specify additional parameters, you’ll also have to give the launch plan a unique name. Default and fixed inputs can be expressed as Python native values like so:
launch_plan.LaunchPlan.get_or_create( workflow=wf, name="your_lp_name_1", default_inputs={"a": 3}, fixed_inputs={"c": "4"} )
Additionally, a launch plan can be configured to run on a schedule and emit notifications.
Please see the relevant Schedule and Notification objects as well.
To configure the remaining parameters, you’ll need to import the relevant model objects as well.
sched = CronSchedule("* * ? * * *", kickoff_time_input_arg="abc") email_notif = notification.Email( phases=[_execution_model.WorkflowExecutionPhase.SUCCEEDED], recipients_email=["my-team@email.com"] ) launch_plan.LaunchPlan.get_or_create( workflow=wf, name="your_lp_name_2", schedule=sched, notifications=[email_notif] )
from flytekit.models.common import Annotations, AuthRole, Labels, RawOutputDataConfig
Then use as follows
auth_role_model = AuthRole(assumable_iam_role="my:iam:role") launch_plan.LaunchPlan.get_or_create( workflow=wf, name="your_lp_name_3", ) labels_model = Labels({"label": "foo"}) annotations_model = Annotations({"annotate": "bar"}) launch_plan.LaunchPlan.get_or_create( workflow=wf, name="your_lp_name_4", auth_role=auth_role_model, labels=labels_model, annotations=annotations_model, ) raw_output_data_config = RawOutputDataConfig("s3://foo/output") launch_plan.LaunchPlan.get_or_create( workflow=wf, name="your_lp_name_5", raw_output_data_config=raw_output_data_config )
- Parameters:
name (str)
workflow (_annotated_workflow.WorkflowBase)
parameters (_interface_models.ParameterMap)
fixed_inputs (_literal_models.LiteralMap)
schedule (Optional[_schedule_model.Schedule])
notifications (Optional[List[_common_models.Notification]])
labels (Optional[_common_models.Labels])
annotations (Optional[_common_models.Annotations])
raw_output_data_config (Optional[_common_models.RawOutputDataConfig])
max_parallelism (Optional[int])
security_context (Optional[security.SecurityContext])
trigger (Optional[LaunchPlanTriggerBase])
overwrite_cache (Optional[bool])
Exception Handling¶
Exception handling occurs along two dimensions:
System vs. User: We distinguish between Flytekit/system-level exceptions and user exceptions. For instance, if Flytekit encounters an issue while uploading outputs, it is considered a system exception. On the other hand, if a user raises a
ValueErrordue to an unexpected input in the task code, it is classified as a user exception.Recoverable vs. Non-recoverable: Recoverable errors are retried and counted towards the task’s retry count, while non-recoverable errors simply fail. System exceptions are recoverable by default since they are usually temporary.
The following is the user exception tree, which users can raise as needed. It is important to note that only FlyteRecoverableException is a recoverable exception. All other exceptions, including non-Flytekit defined exceptions, are non-recoverable.
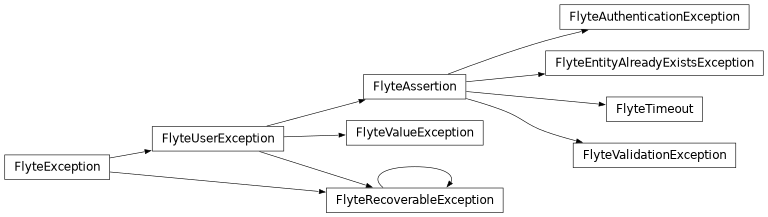
Implementation¶
If you wish to delve deeper, you can explore the FlyteScopedException classes.
There are two decorators that are used throughout the codebase.
- flytekit.exceptions.scopes.system_entry_point(wrapped, args, kwargs)[source]¶
The reason these two (see the user one below) decorators exist is to categorize non-Flyte exceptions at arbitrary locations. For example, while there is a separate ecosystem of Flyte-defined user and system exceptions (see the FlyteException hierarchy), and we can easily understand and categorize those, if flytekit comes upon a random
ValueErroror other non-flytekit defined error, how would we know if it was a bug in flytekit versus an error with user code or something the user called? The purpose of these decorators is to categorize those (see the last case in the nested try/catch below.Decorator for wrapping functions that enter a system context. This should decorate every method that may invoke some user code later on down the line. This will allow us to add differentiation between what is a user error and what is a system failure. Furthermore, we will clean the exception trace so as to make more sense to the user – allowing them to know if they should take action themselves or pass on to the platform owners. We will dispatch metrics and such appropriately.
- flytekit.exceptions.scopes.user_entry_point(wrapped, args, kwargs)[source]¶
See the comment for the system_entry_point above as well.
Decorator for wrapping functions that enter into a user context. This will help us differentiate user-created failures even when it is re-entrant into system code.
Note: a user_entry_point can ONLY ever be called from within a @system_entry_point wrapped function, therefore, we can always ensure we will hit a system_entry_point to correctly reformat our exceptions. Also, any exception we create here will only be handled within our system code so we don’t need to worry about leaking weird exceptions to the user.
Call Patterns¶
The entities mentioned above (tasks, workflows, and launch plans) are callable and can be invoked to generate one or more units of work in Flyte.
In Pythonic terminology, adding () to the end of an entity invokes the __call__ method on the object.
The behavior that occurs when a callable entity is invoked is dependent on the current context, specifically the current flytekit.FlyteContext.
Raw task execution¶
When a task is executed as part of a unit test, the @task decorator transforms the decorated function into an instance of the PythonFunctionTask object.
However, when a user invokes the task() function outside of a workflow, the original function is called without any intervention from Flytekit.
Task execution inside a workflow¶
When a workflow is executed locally (for instance, as part of a unit test), some modifications are made to the task.
Before proceeding, it is worth noting a special object, the flytekit.extend.Promise.
- class flytekit.core.promise.Promise(var, val)[source]
This object is a wrapper and exists for three main reasons. Let’s assume we’re dealing with a task like
@task def t1() -> (int, str): ...
Handling the duality between compilation and local execution - when the task function is run in a local execution mode inside a workflow function, a Python integer and string are produced. When the task is being compiled as part of the workflow, the task call creates a Node instead, and the task returns two Promise objects that point to that Node.
One needs to be able to call
x = t1().with_overrides(...)
If the task returns an integer or a
(int, str)tuple liket1above, callingwith_overrideson the result would throw an error. This Promise object adds that.Assorted handling for conditionals.
- Parameters:
var (str)
val (Union[NodeOutput, _literals_models.Literal])
Consider the following workflow:
@task
def t1(a: int) -> Tuple[int, str]:
return a + 2, "world"
@task
def t2(a: str, b: str) -> str:
return b + a
@workflow
def my_wf(a: int, b: str) -> Tuple[int, str]:
x, y = t1(a=a).with_overrides(...)
d = t2(a=y, b=b)
return x, d
As stated in the documentation for the Promise object, when a task is invoked within a workflow, the Python native values returned by the underlying functions are first converted into Flyte IDL literals and then encapsulated inside Promise objects. One Promise object is created for each return variable.
When the next task is invoked, the values are extracted from these Promises.
Compilation¶
During the workflow compilation process, instead of generating Promise objects that encapsulate literal values, the workflow encapsulates a flytekit.core.promise.NodeOutput.
This approach aids in tracking the data dependencies between tasks.
Branch Skip¶
If the condition specified in a flytekit.conditional() evaluates to False, Flytekit will avoid invoking the corresponding task.
This prevents the unintended execution of the task.
Note
The execution pattern that we discussed for tasks can be applied to workflows and launch plans as well!