FlytePropeller Architecture#
Note
In the frame of this document, we use the term “workflow” to describe the single execution of a workflow definition.
Introduction#
A Flyte workflow is represented as a Directed Acyclic Graph (DAG) of interconnected Nodes. Flyte supports a robust collection of Node types to ensure diverse functionality.
TaskNodessupport a plugin system to externally add system integrations.BranchNodesallow altering the control flow during runtime; pruning downstream evaluation paths based on input.DynamicNodesadd nodes to the DAG.WorkflowNodesallow embedding workflows within each other.
FlytePropeller is responsible for scheduling and tracking execution of Flyte workflows. It is implemented using a K8s controller that follows the reconciler pattern.
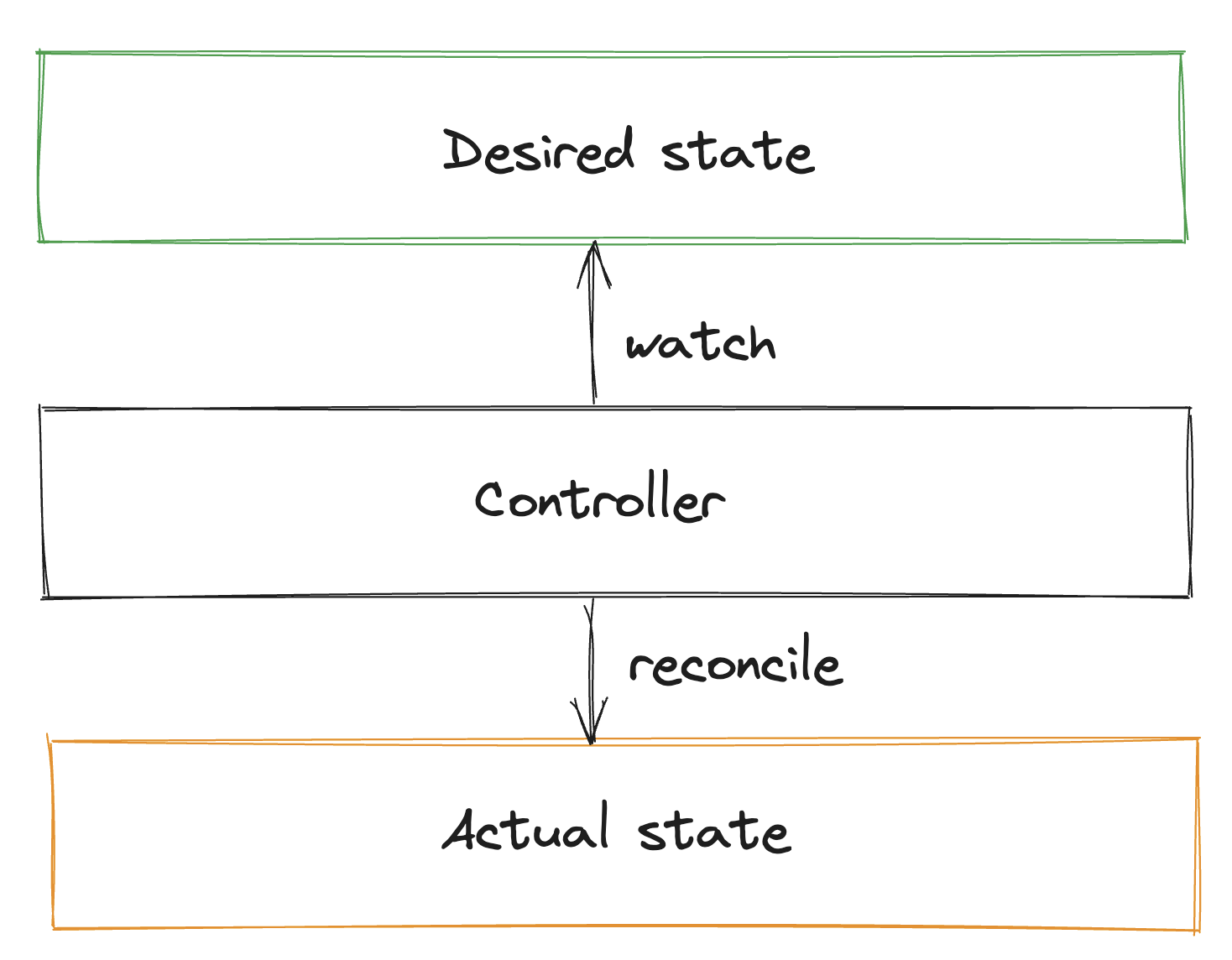
In this scheme, resources are periodically evaluated and the goal is to transition from the observed state to a requested state.
In our case, workflows are the resources, whose desired stated (workflow definition) is expressed using Flyte’s SDK. Workflows are iteratively evaluated to transition from the current state to success. During each evaluation loop, the current workflow state is established as the phase of workflow nodes and subsequent tasks, and FlytePropeller performs operations to transition this state to success. The operations may include scheduling (or rescheduling) node executions, evaluating dynamic or branch nodes, etc.
By using a simple yet robust mechanism, FlytePropeller can scale to manage a large number of concurrent workflows without significant performance degradation.
This document attempts to break down the FlytePropeller architecture by tracking workflow life cycle through each internal component. Below is a high-level illustration of the FlytePropeller architecture and a flow chart of each component’s responsibilities during FlyteWorkflow execution.
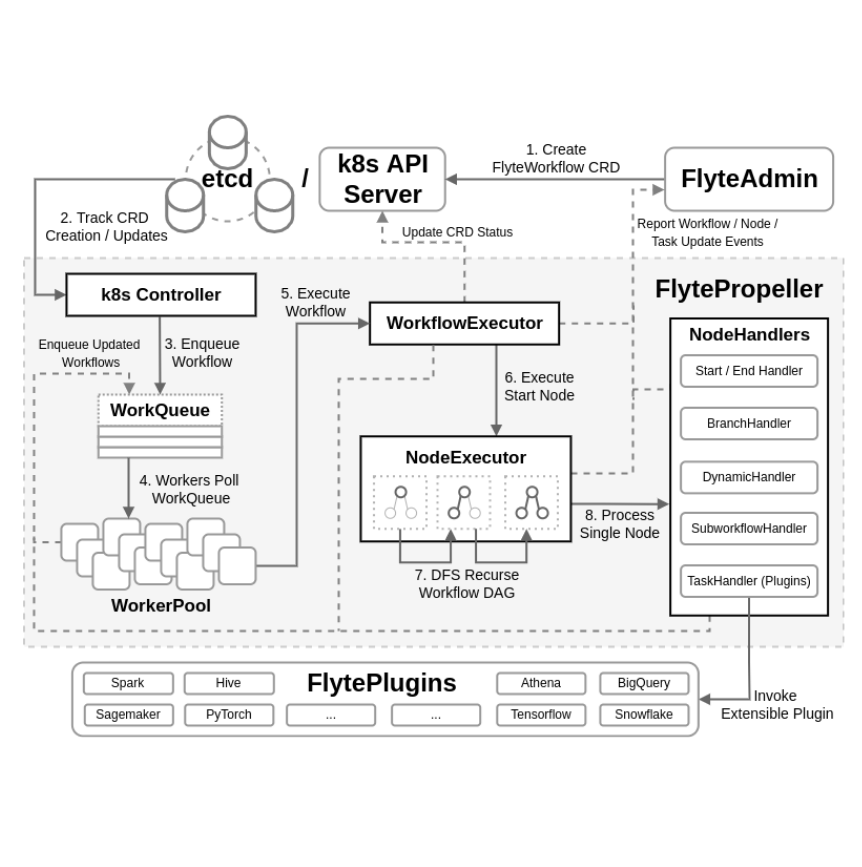
Components#
FlyteAdmin is the common entry point, where initialization of FlyteWorkflow Custom Resources may be triggered by user workflow definition executions, automatic relaunches, or periodically scheduled workflow definition executions.
FlyteWorkflow CRD / K8s Integration#
Workflows in Flyte are maintained as Custom Resource Definitions (CRDs) in Kubernetes, which are stored in the backing etcd key-value store. Each workflow execution results in the creation of a new flyteworkflow CR (Custom Resource) which maintains its state for the duration of the execution. CRDs provide variable definitions to describe both resource specifications (spec) and status (status). The flyteworkflow CRD uses the spec subsection to detail the workflow DAG, embodying node dependencies, etc.
Example
Execute an example workflow on a remote Flyte cluster:
pyflyte run --remote example.py training_workflow --hyperparameters '{"C": 0.4}'
Verify there’s a new Custom Resource on the
flytesnacks-developmentnamespace (this is, the workflow belongs to theflytesnacksproject and thedevelopmentdomain):
kubectl get flyteworkflows.flyte.lyft.com -n flytesnacks-development
Example output:
NAME AGE
f7616dc75400f43e6920 3h42m
Describe the contents of the Custom Resource, for example the
specsection:
kubectl describe flyteworkflows.flyte.lyft.com f7616dc75400f43e6920 -n flytesnacks-development
"spec": {
"connections": {
"n0": [
"n1"
],
"n1": [
"n2"
],
"n2": [
"end-node"
],
"start-node": [
"n0",
"n2"
]
},
The status subsection tracks workflow metadata including overall workflow status, node/task phases, status/phase transition timestamps, etc.
"status": {
"dataDir": "gs://flyteontf-gcp-data-116223838137/metadata/propeller/flytesnacks-development-f7616dc75400f43e6920",
"defVersion": 1,
"lastUpdatedAt": "2024-03-26T16:22:16Z",
"nodeStatus": {
"end-node": {
"phase": 5,
"stoppedAt": "2024-03-26T16:22:16Z"
},
"n0": {
"phase": 5,
"stoppedAt": "2024-03-26T16:21:46Z"
},
"n1": {
"phase": 5,
"stoppedAt": "2024-03-26T16:22:02Z"
},
"n2": {
"phase": 5,
"stoppedAt": "2024-03-26T16:22:16Z"
},
"start-node": {
"phase": 5,
"stoppedAt": "2024-03-26T16:20:39Z"
}
},
K8s exposes a powerful controller/operator API that enables entities to track creation/updates over a specific resource type. FlytePropeller uses this API to track FlyteWorkflows, meaning every time an instance of the flyteworkflow CR is created/updated, the FlytePropeller instance is notified.
Note
Manual creation of flyteworkflow CRs, without the intervention of flyteadmin, is possible but not supported as the resulting resource will have limited visibility and usability.
WorkQueue/WorkerPool#
FlytePropeller supports concurrent execution of multiple, unique workflows using a WorkQueue and WorkerPool.
The WorkQueue is a FIFO queue storing workflow ID strings that require a lookup to retrieve the FlyteWorkflow CR to ensure up-to-date status. A workflow may be added to the queue in a variety of circumstances:
A new FlyteWorkflow CR is created or an existing instance is updated
The K8s Informer detects a workflow timeout or failed liveness check during its periodic resync operation on the FlyteWorkflow.
A FlytePropeller worker experiences an error during a processing loop
The WorkflowExecutor observes a completed downstream node
A NodeHandler observes state change and explicitly enqueues its owner. (For example, K8s pod informer observes completion of a task.)
The WorkerPool is implemented as a collection of goroutines, one for each worker. Using this lightweight construct, FlytePropeller can scale to 1000s of workers on a single CPU. Workers continually poll the WorkQueue for workflows. On success, the workflow is passed to the WorkflowExecutor.
WorkflowExecutor#
The WorkflowExecutor is responsible for handling high-level workflow operations. This includes maintaining the workflow phase (for example: running, failing, succeeded, etc.) according to the underlying node phases and administering pending cleanup operations. For example, aborting existing node evaluations during workflow failures or removing FlyteWorkflow CRD finalizers on completion to ensure the CR is deleted. Additionally, at the conclusion of each evaluation round, the WorkflowExecutor updates the FlyteWorkflow CR with updated metadata fields to track the status between evaluation iterations.
NodeExecutor#
The NodeExecutor is executed on a single node, beginning with the workflow’s start node. It traverses the workflow using a visitor pattern with a modified depth-first search (DFS), evaluating each node along the path. A few examples of node evaluation based on phase include:
Successful nodes are skipped
Unevaluated nodes are queued for processing
Failed nodes may be reattempted up to a configurable threshold.
There are many configurable parameters to tune evaluation criteria including max parallelism which restricts the number of nodes which may be scheduled concurrently. Additionally, nodes may be retried to ensure recoverability on failure.
Go to the Optimizing Performance section for more information on how to tune Propeller parameters.
The NodeExecutor is also responsible for linking data readers/writers to facilitate data transfer between node executions. The data transfer process occurs automatically within Flyte, using efficient K8s events rather than a polling listener pattern which incurs more overhead. Relatively small amounts of data may be passed between nodes inline, but it is more common to pass data URLs to backing storage. A component of this is writing to and checking the data cache, which facilitates the reuse of previously completed evaluations.
NodeHandlers#
FlytePropeller includes a robust collection of NodeHandlers to support diverse evaluation of the workflow DAG:
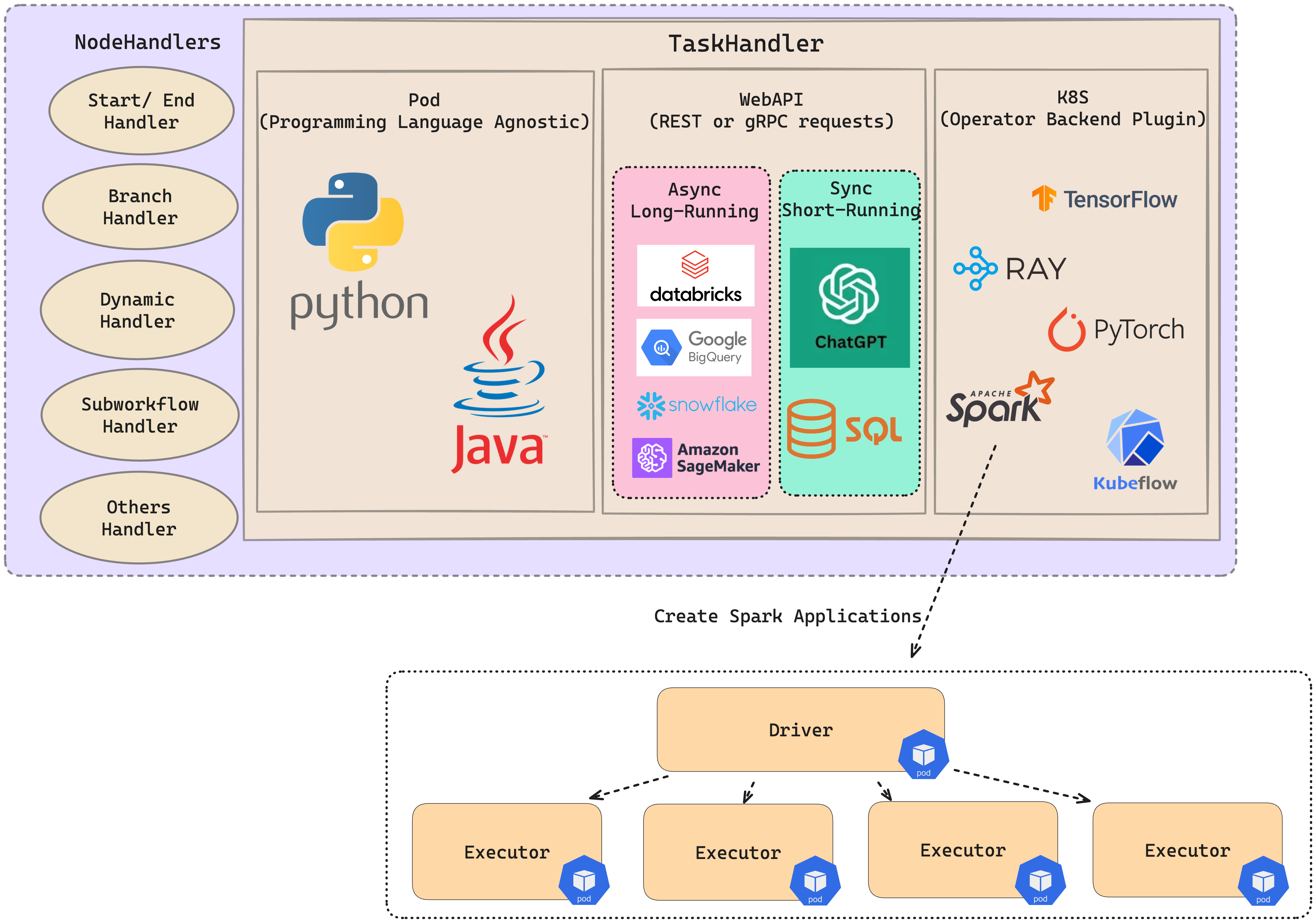
TaskHandler (Plugins): These are responsible for executing tasks in the Flyte cluster. There are mainly 3 kinds of tasks for the task handler:
Pod Task: Create a pod in the Kubernetes cluster, execute the task, and then delete the pod.
K8s Operator Backend Plugin: Install a specific Kubernetes Operator (e.g., Spark, Ray, or Kubeflow) in the cluster, create pods by the Kubernetes Operator, execute the task, and then delete the pods.
Web API Task: Send REST/gRPC requests to a server and return the response. Note: The Web API Task will not start a pod.
DynamicHandler: Flyte workflow CRs are initialized using a DAG compiled during the registration process. The numerous benefits of this approach are beyond the scope of this document. However, there are situations where the complete DAG is unknown at compile time. For example, when executing a task on each value of an input list. Using Dynamic nodes, a new DAG subgraph may be dynamically compiled during runtime and linked to the existing FlyteWorkflow CR.
WorkflowHandler: This handler allows embedding workflows within another workflow definition. The API exposes this functionality using either (1) an inline execution, where the workflow function is invoked directly resulting in a single FlyteWorkflow CR with an appended sub-workflow, or (2) a launch plan, which uses a TODO to create a separate sub-FlyteWorkflow CR whose execution state is linked to the parent FlyteWorkflow CR.
BranchHandler: The branch handler allows the DAG to follow a specific control path based on input (or computed) values.
Start / End Handlers: These are dummy handlers which process input and output data and in turn transition start and end nodes to success.
FlyteAdmin Events#
It should be noted that the WorkflowExecutor, NodeExecutor, and TaskHandlers send events to FlyteAdmin, enabling it to track workflows in near real-time.
FlytePlugins#
Every operation that Propeller performs makes use of a plugin. The following diagram describe the different types of plugins available for Propeller and an example operation when using the Spark integration: