Understand How Flyte Handles Data¶
Types of Data¶
There are two parts to the data in Flyte:
Metadata
It consists of data about inputs to a task, and other artifacts.
It is configured globally for FlytePropeller, FlyteAdmin etc., and the running pods/jobs need access to this bucket to get the data.
Raw data
It is the actual data (such as the Pandas DataFrame, Spark DataFrame, etc.).
Raw data paths are unique for every execution, and the prefixes can be modified per execution.
None of the Flyte control plane components would access the raw data. This provides great separation of data between the control plane and the data plane.
Let us consider a simple Python task:
@task
def my_task(m: int, n: str, o: FlyteFile) -> pd.DataFrame:
...
In the above code sample, m, n, o are inputs to the task.
m of type int and n of type str are simple primitive types, while o is an arbitrarily sized file.
All of them from Flyte’s point of view are data.
The difference lies in how Flyte stores and passes each of these data items.
For every task that receives input, Flyte sends an Inputs Metadata object, which contains all the primitive or simple scalar values inlined, but in the case of
complex, large objects, they are offloaded and the Metadata simply stores a reference to the object. In our example, m and n are inlined while
o and the output pd.DataFrame are offloaded to an object store, and their reference is captured in the metadata.
Flytekit TypeTransformers make it possible to use complex objects as if they are available locally - just like persistent filehandles. But Flyte backend only deals with the references.
Thus, primitive data types and references to large objects fall under Metadata - Meta input or Meta output, and the actual large object is known as Raw data. A unique property of this separation is that all meta values are read by FlytePropeller engine and available on the FlyteConsole or CLI from the control plane. Raw data is not read by any of the Flyte components and hence it is possible to store it in a completely separate blob storage or alternate stores, which can’t be accessed by Flyte control plane components but can be accessed by users’s container/tasks.
Raw Data Prefix¶
Every task can read/write its own data files. If FlyteFile or any natively supported type like pandas.DataFrame is used, Flyte will automatically offload and download
data from the configured object-store paths. These paths are completely customizable per LaunchPlan or Execution.
The default Rawoutput path (prefix in an object store like S3/GCS) can be configured during registration as shown in flytectl register files. The argument
--outputLocationPrefixallows us to set the destination directory for all the raw data produced. Flyte will create randomized folders in this path to store the data.To override the
RawOutputpath (prefix in an object store like S3/GCS), you can specify an alternate location when invoking a Flyte execution, as shown in the following screenshot of the LaunchForm in FlyteConsole:
In the sandbox, the default Rawoutput-prefix is configured to be the root of the local bucket. Hence Flyte will write all the raw data (reference types like blob, file, df/schema/parquet, etc.) under a path defined by the execution.
Metadata¶
Metadata in Flyte is critical to enable the passing of data between tasks. It allows to perform in-memory computations for branches or send partial outputs from one task to another or compose outputs from multiple tasks into one input to be sent to a task.
Thus, metadata is restricted due to its omnipresence. Each meta output/input cannot be larger than 1MB. If you have List[int], it cannot be larger than 1MB, considering other input entities. In scenarios where large lists or strings need to be sent between tasks, file abstraction is preferred.
LiteralType & Literals¶
SERIALIZATION TIME¶
When a task is declared with inputs and outputs, Flyte extracts the interface of the task and converts it to an internal representation called a TypedInterface. For each variable, a corresponding LiteralType is created.
For example, the following Python function’s interface is transformed as follows:
@task
def my_task(a: int, b: str) -> FlyteFile:
"""
Description of my function
:param a: My input integer
:param b: My input string
:return: My output file
"""
...
interface {
inputs {
variables {
key: "a"
value {
type {
simple: INTEGER
}
description: "My input Integer"
}
}
variables {
key: "b"
value {
type {
simple: STRING
}
description: "My input string"
}
}
}
outputs {
variables {
key: "o0"
value {
type {
blob {
}
}
description: "My output File"
}
}
}
}
RUNTIME¶
At runtime, data passes through Flyte using Literal where the values are set.
For files, the corresponding Literal is called LiteralBlob (Blob) which is a binary large object.
Many different objects can be mapped to the underlying Blob or Struct types. For example, an image is a Blob, a pandas.DataFrame is a Blob of type parquet, etc.
Data Movement¶
Flyte is primarily a DataFlow Engine. It enables movement of data and provides an abstraction to enable movement of data between different languages.
One implementation of Flyte is the current workflow engine.
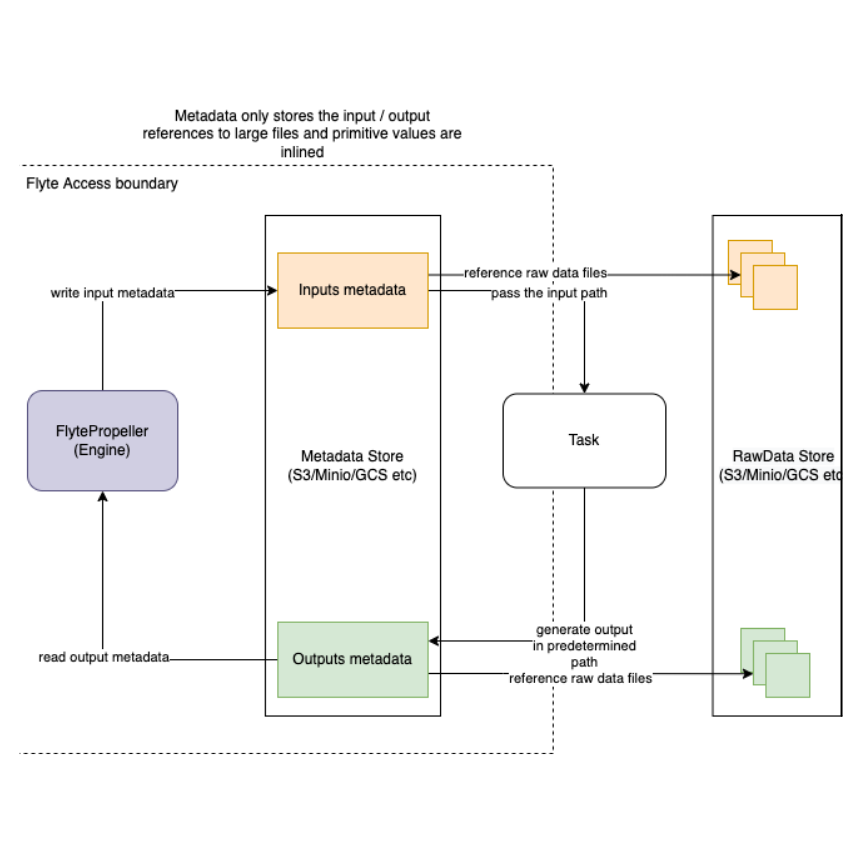
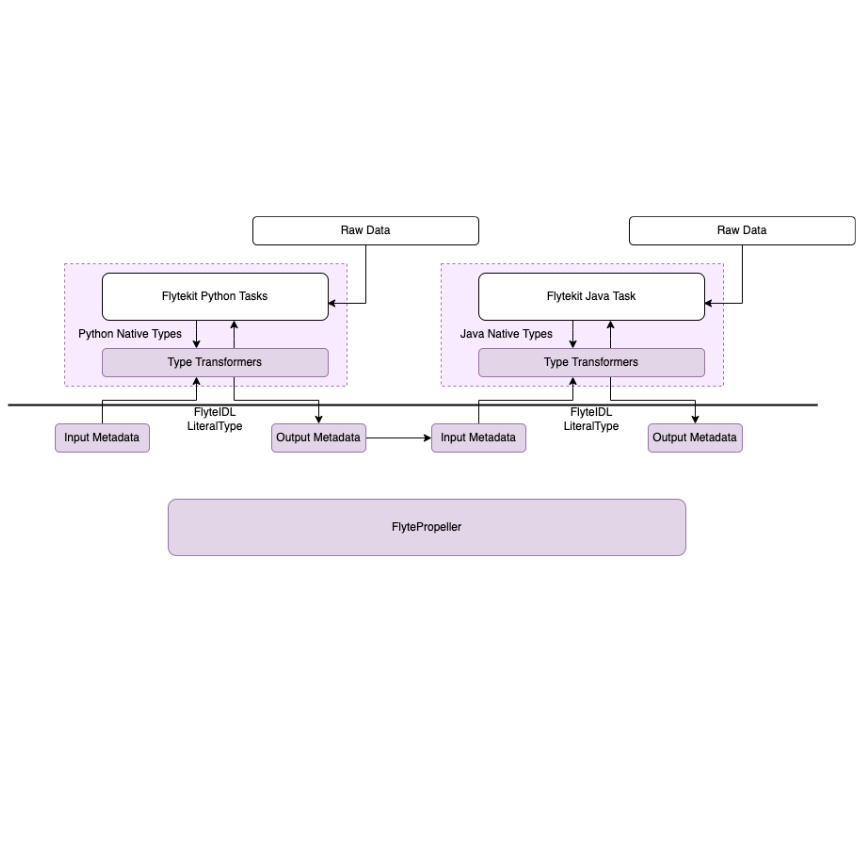
The workflow engine is responsible for moving data from a previous task to the next task. As explained previously, Flyte only deals with Metadata and not the actual Raw data. The illustration below explains how data flows from engine to the task and how that is transferred between tasks. The medium to transfer the data can change, and will change in the future. We could use fast metadata stores to speed up data movement or exploit locality.
Between Flytepropeller and Tasks¶
Between Tasks¶
Bringing in Your Own Datastores for Raw Data¶
Flytekit has a pluggable data persistence layer.
This is driven by PROTOCOL.
For example, it is theoretically possible to use S3 s3:// for metadata and GCS gcs:// for raw data. It is also possible to create your own protocol my_fs://, to change how data is stored and accessed.
But for Metadata, the data should be accessible to Flyte control plane.
Data persistence is also pluggable. By default, it supports all major blob stores and uses an interface defined in Flytestdlib.