Component Architecture¶
This document aims to demystify how Flyte’s major components Flyteidl, Flytekit, Flytectl, FlyteConsole, FlyteAdmin, FlytePropeller, and FlytePlugins fit together at a high level.
FlyteIDL¶
In Flyte, entities like “Workflows”, “Tasks”, “Launch Plans”, and “Schedules” are recognized by multiple system components. For components to communicate effectively, they need a shared understanding about the structure of these entities.
Flyteidl (Interface Definition Language) is where shared Flyte entities are defined. It also defines the RPC service definition for the core Flyte API.
Flyteidl uses the protobuf schema to describe entities. Clients are generated for Python, Golang, and JavaScript and imported by Flyte components.
Planes¶
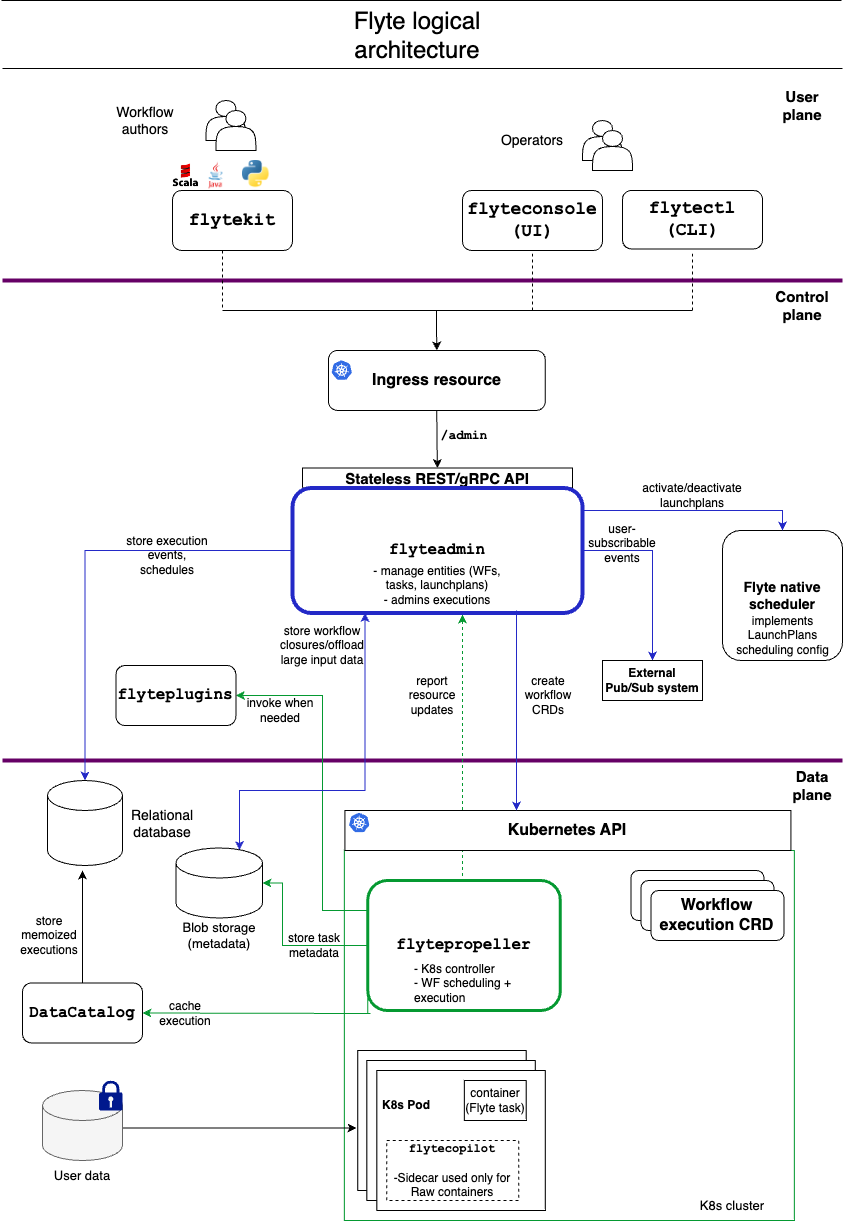
Flyte components are separated into 3 logical planes. The planes are summarized and explained in detail below. The goal is that these planes can be replaced by alternate implementations.
User Plane |
The User Plane consists of all user tools that assist in interacting with the core Flyte API. These tools include the FlyteConsole, Flytekit, and Flytectl. |
Control Plane |
The Control Plane implements the core Flyte API. It serves all client requests coming from the User Plane. It stores information such as current and past running workflows, and provides that information upon request. It also accepts requests to execute workflows, but offloads the work to the Data Plane. |
Data Plane |
The sole responsibility of the the Data Plane is to fulfill workflows. It accepts workflow requests from the Control Plane and guides the workflow to completion, launching tasks on a cluster of machines as necessary based on the workflow graph. It sends status events back to the control plane so the information can be stored and surfaced to end-users. |
User Plane¶
In Flyte, workflows are represented as a Directed Acyclic Graph (DAG) of tasks. While this representation is logical for services, managing workflow DAGs in this format is a tedious exercise for humans. The Flyte User Plane provides tools to create, manage, and visualize workflows in a format that is easily digestible to the users.
These tools include:
- Flytekit
Flytekit is an SDK that helps users design new workflows using the Python programming language. It can parse the Python code, compile it into a valid Workflow DAG, and submit it to Flyte for execution.
- FlyteConsole
FlyteConsole provides the Web interface for Flyte. Users and administrators can use the console to view workflows, launch plans, schedules, tasks, and individual task executions. The console provides tools to visualize workflows, and surfaces relevant logs for debugging failed tasks.
- Flytectl
Flytectl provides interactive access to Flyte to launch and access workflows via terminal.
Control Plane¶
The Control Plane supports the core REST/gRPC API defined in Flyteidl. User Plane tools like FlyteConsole and Flytekit contact the control plane on behalf of users to store and retrieve information.
Currently, the entire control plane is handled by a single service called FlyteAdmin.
FlyteAdmin is stateless. It processes requests to create entities like tasks, workflows, and schedules by persisting data in a relational database.
While FlyteAdmin serves the Workflow Execution API, it does not itself execute workflows. To launch workflow executions, FlyteAdmin sends the workflow DAG to the DataPlane. For added scalability and fault-tolerance, FlyteAdmin can be configured to load-balance workflows across multiple isolated data-plane clusters.
Data Plane¶
The Data Plane is the engine that accepts DAGs, and fulfills workflow executions by launching tasks in the order defined by the graph. Requests to the Data Plane generally come via the control plane, and not from end-users.
In order to support compute-intensive workflows at massive scale, the Data Plane needs to launch containers on a cluster of machines. The current implementation leverages Kubernetes for cluster management.
Unlike the user-facing Control Plane, the Data Plane does not expose a traditional REST/gRPC API. To launch an execution in the Data Plane, you create a “flyteworkflow” resource in Kubernetes. A “flyteworkflow” is a Kubernetes Custom Resource (CRD) created by our team. This custom resource represents the Flyte workflow DAG.
The core state machine that processes flyteworkflows is the worker known as FlytePropeller.
FlytePropeller leverages the Kubernetes operator pattern. It polls the Kubernetes API, looking for newly created flyteworkflow resources. FlytePropeller understands the workflow DAG, and launches the appropriate Kubernetes pods as needed to complete tasks. It periodically checks for completed tasks, launching downstream tasks until the workflow is complete.
Plugins
Each task in a flyteworkflow DAG has a specified type. The logic for fulfilling a task is determined by its task type. In the basic case, FlytePropeller launches a single Kubernetes pod to fulfill a task. Complex task types require workloads to be distributed across hundreds of pods.
The type-specific task logic is separated into isolated code modules known as plugins. Each task type has an associated plugin that is responsible for handling tasks of its type. For each task in a workflow, FlytePropeller activates the appropriate plugin based on the task type in order to fulfill the task.
The Flyte team has pre-built plugins for Hive, Spark, AWS Batch, and more. To support new use-cases, developers can create their own plugins and bundle them in their FlytePropeller deployment.