Nested parallelization¶
For exceptionally large or complicated workflows that can’t be adequately implemented as dynamic workflows or map tasks, it can be beneficial to have multiple levels of workflow parallelization.
This is useful for multiple reasons:
Better code organization
Better code reuse
Better testing
Better debugging
Better monitoring, since each subworkflow can be run independently and monitored independently
Better performance and scale, since each subworkflow is executed as a separate workflow and thus can be distributed among different flytepropeller workers and shards. This allows for better parallelism and scale.
Nested dynamic workflows¶
You can use nested dynamic workflows to break down a large workflow into smaller workflows and then compose them together to form a hierarchy. In this example, a top-level workflow uses two levels of dynamic workflows to process a list through some simple addition tasks and then flatten the list again.
Example code¶
"""
A core workflow parallelized as six items with a chunk size of two will be structured as follows:
multi_wf -> level1 -> level2 -> core_wf -> step1 -> step2
-> core_wf -> step1 -> step2
level2 -> core_wf -> step1 -> step2
-> core_wf -> step1 -> step2
level2 -> core_wf -> step1 -> step2
-> core_wf -> step1 -> step2
"""
import typing
from flytekit import task, workflow, dynamic, LaunchPlan
@task
def step1(a: int) -> int:
return a + 1
@task
def step2(a: int) -> int:
return a + 2
@workflow
def core_wf(a: int) -> int:
return step2(a=step1(a=a))
core_wf_lp = LaunchPlan.get_or_create(core_wf)
@dynamic
def level2(l: typing.List[int]) -> typing.List[int]:
return [core_wf_lp(a=a) for a in l]
@task
def reduce(l: typing.List[typing.List[int]]) -> typing.List[int]:
f = []
for i in l:
f.extend(i)
return f
@dynamic
def level1(l: typing.List[int], chunk: int) -> typing.List[int]:
v = []
for i in range(0, len(l), chunk):
v.append(level2(l=l[i:i + chunk]))
return reduce(l=v)
@workflow
def multi_wf(l: typing.List[int], chunk: int) -> typing.List[int]:
return level1(l=l, chunk=chunk)
Overrides let you add additional arguments to the launch plan you are looping over in the dynamic. Here we add caching:
@task
def increment(num: int) -> int:
return num + 1
@workflow
def child(num: int) -> int:
return increment(num=num)
child_lp = LaunchPlan.get_or_create(child)
@dynamic
def spawn(n: int) -> List[int]:
l = []
for i in [1,2,3,4,5]:
l.append(child_lp(num=i).with_overrides(cache=True, cache_version="1.0.0"))
# you can also pass l to another task if you want
return l
Flyte console¶
Here is a visual representation of the execution of nested dynamic workflows in the Flyte console:
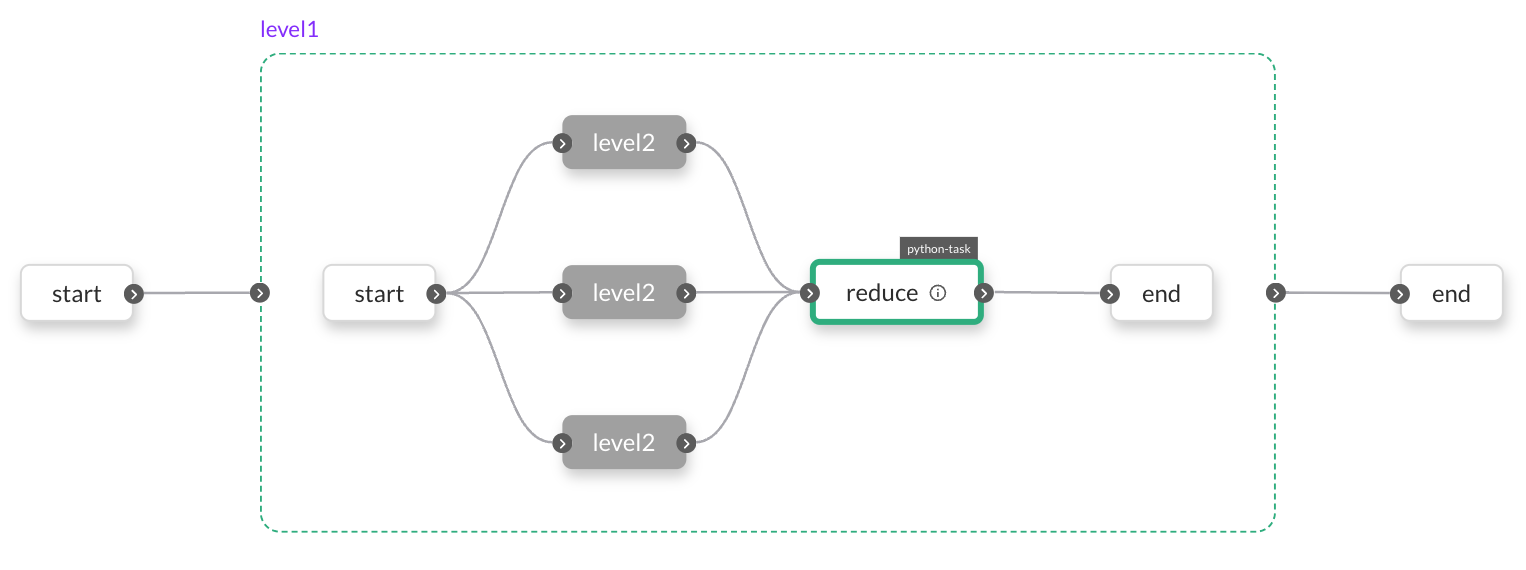
In each level2 node at the top level, two core workflows are run in parallel:
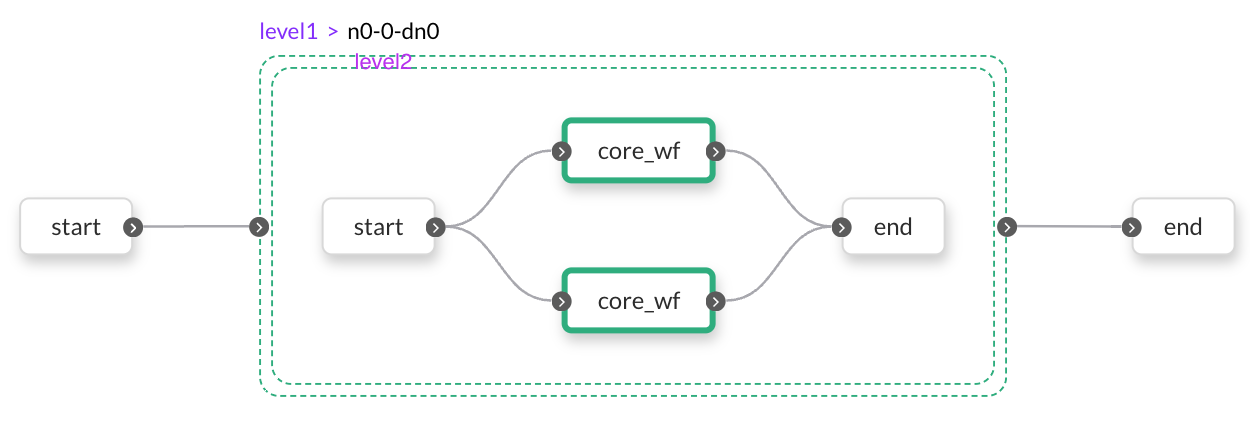
Finally, in each core workflow, the two tasks are executed in series:

Mixed parallelism¶
This example is similar to nested dynamic workflows, but instead of using a dynamic workflow to parallelize a core workflow with serial tasks, we use a core workflow to call a map task, which processes both inputs in parallel. This workflow has one less layer of parallelism, so the outputs won’t be the same as those of the nested parallelization example, but it does still demonstrate how you can mix these different approaches to achieve concurrency.
Example code¶
"""
A core workflow parallelized as six items with a chunk size of two will be structured as follows:
multi_wf -> level1 -> level2 -> mappable
-> mappable
level2 -> mappable
-> mappable
level2 -> mappable
-> mappable
"""
import typing
from flytekit import task, workflow, dynamic, map_task
@task
def mappable(a: int) -> int:
return a + 2
@workflow
def level2(l: typing.List[int]) -> typing.List[int]:
return map_task(mappable)(a=l)
@task
def reduce(l: typing.List[typing.List[int]]) -> typing.List[int]:
f = []
for i in l:
f.extend(i)
return f
@dynamic
def level1(l: typing.List[int], chunk: int) -> typing.List[int]:
v = []
for i in range(0, len(l), chunk):
v.append(level2(l=l[i : i + chunk]))
return reduce(l=v)
@workflow
def multi_wf(l: typing.List[int], chunk: int) -> typing.List[int]:
return level1(l=l, chunk=chunk)
Flyte console¶
While the top-level dynamic workflow will be exactly the same as the nested dynamic workflows example, the inner map task nodes will be visible as links in the sidebar:

Design considerations¶
While you can nest even further if needed, or incorporate map tasks if your inputs are all the same type, the design of your workflow should be informed by the actual data you’re processing. For example, if you have a big library of music from which you’d like to extract the lyrics, the first level could loop through all the albums, and the second level could process each song.
If you’re just processing an enormous list of the same input, it’s best to keep your code simple and let the scheduler handle optimizing the execution. Additionally, unless you need dynamic workflow features like mixing and matching inputs and outputs, it’s usually most efficient to use a map task, which has the added benefit of keeping the UI clean.
You can also choose to limit the scale of parallel execution at a few levels. The max_parallelism attribute can be applied at the workflow level and will limit the number of parallel tasks being executed. (This is set to 25 by default.) Within map tasks, you can specify a concurrency argument, which will limit the number of mapped tasks that can run in parallel at any given time.