Testing agents in a local Python environment¶
You can test agents locally without running the backend server.
To test an agent locally, create a class for the agent task that inherits from SyncAgentExecutorMixin or AsyncAgentExecutorMixin.
These mixins can handle synchronous and asynchronous tasks, respectively, and allow flytekit to mimic FlytePropeller’s behavior in calling the agent.
BigQuery example¶
To test the BigQuery agent, copy the following code to a file called bigquery_task.py, modifying as needed.
Note
In some cases, you will need to store credentials in your local environment when testing locally.
For example, you need to set the GOOGLE_APPLICATION_CREDENTIALS environment variable when running BigQuery tasks to test the BigQuery agent.
Add AsyncAgentExecutorMixin or SyncAgentExecutorMixin to the class to tell flytekit to use the agent to run the task.
class BigQueryTask(AsyncAgentExecutorMixin, SQLTask[BigQueryConfig]):
...
class ChatGPTTask(SyncAgentExecutorMixin, PythonTask):
...
Flytekit will automatically use the agent to run the task in the local execution.
bigquery_doge_coin = BigQueryTask(
name=f"bigquery.doge_coin",
inputs=kwtypes(version=int),
query_template="SELECT * FROM `bigquery-public-data.crypto_dogecoin.transactions` WHERE version = @version LIMIT 10;",
output_structured_dataset_type=StructuredDataset,
task_config=BigQueryConfig(ProjectID="flyte-test-340607")
)
You can run the above example task locally and test the agent with the following command:
pyflyte run bigquery_task.py bigquery_doge_coin --version 10
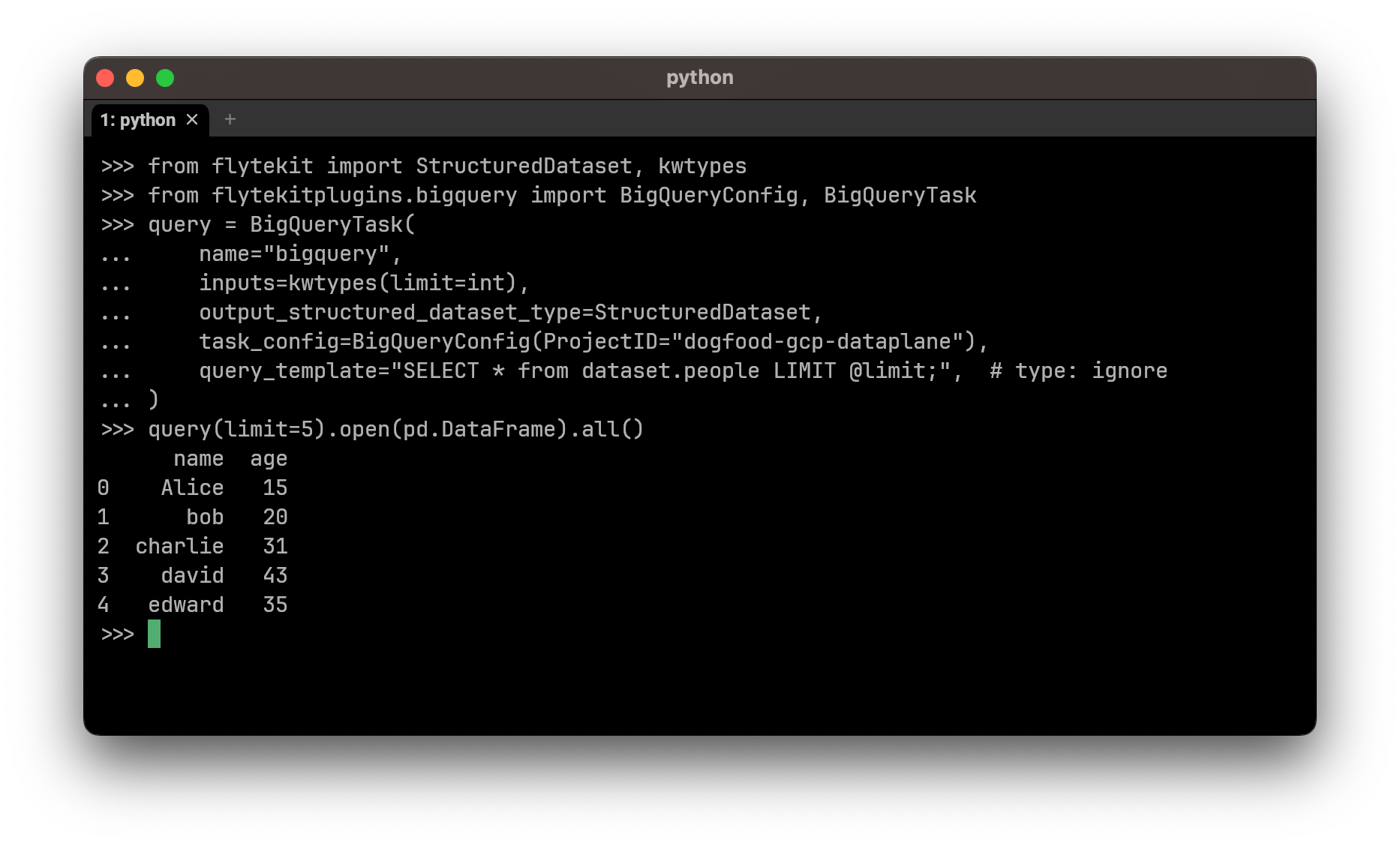
You can also run a BigQuery task in your Python interpreter to test the agent locally.
Databricks example¶
To test the Databricks agent, copy the following code to a file called databricks_task.py, modifying as needed.
@task(task_config=Databricks(...))
def hello_spark(partitions: int) -> float:
print("Starting Spark with Partitions: {}".format(partitions))
n = 100000 * partitions
sess = flytekit.current_context().spark_session
count = (
sess.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
)
pi_val = 4.0 * count / n
print("Pi val is :{}".format(pi_val))
return pi_val
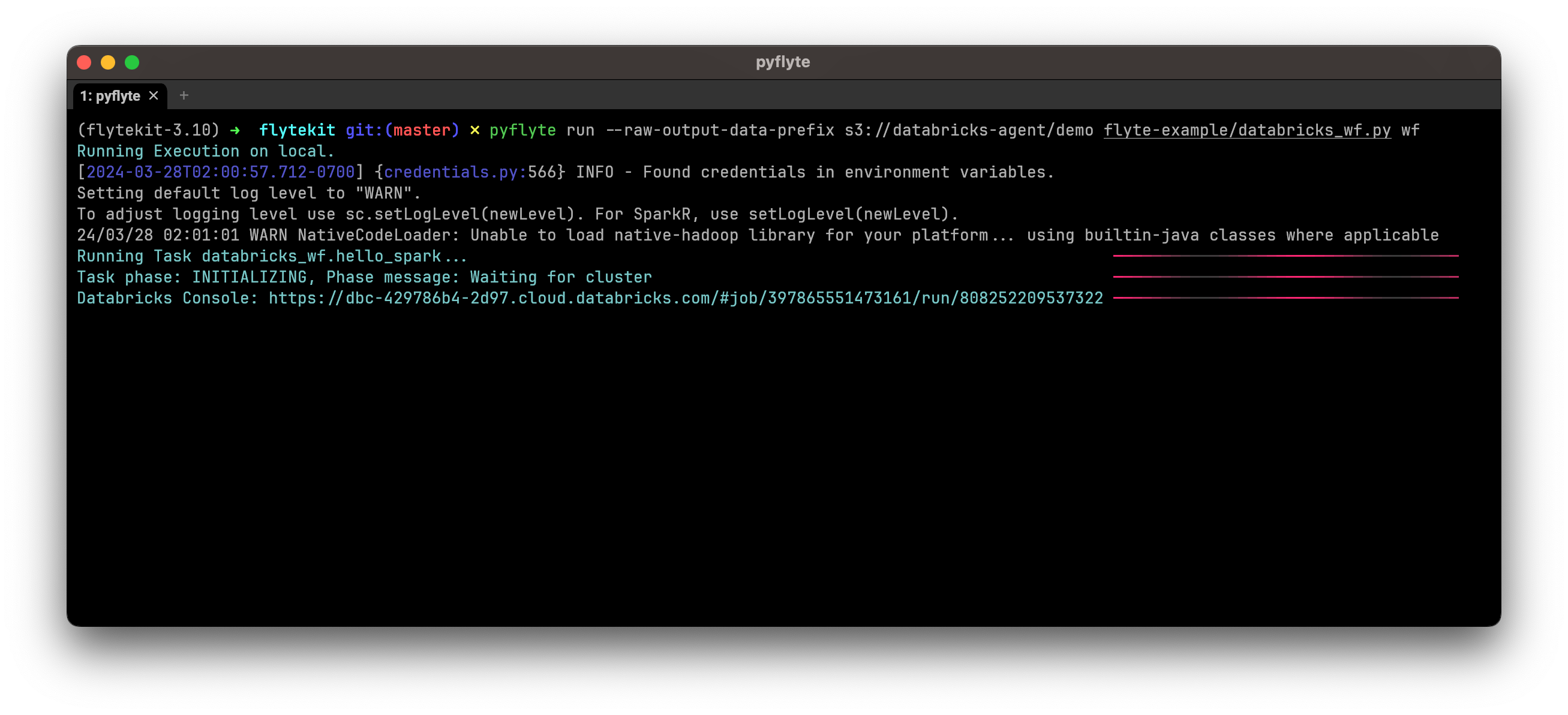
To execute the Spark task on the agent, you must configure the raw-output-data-prefix with a remote path.
This configuration ensures that flytekit transfers the input data to the blob storage and allows the Spark job running on Databricks to access the input data directly from the designated bucket.
Note
The Spark task will run locally if the raw-output-data-prefix is not set.
pyflyte run --raw-output-data-prefix s3://my-s3-bucket/databricks databricks_task.py hello_spark